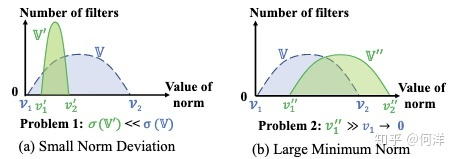
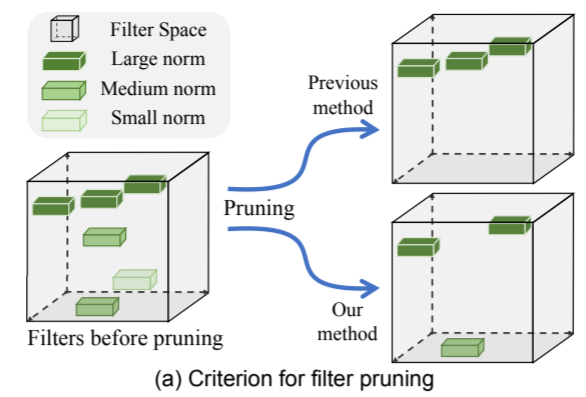
右上角即为传统方法进行剪枝,右下角为作者提出的方法(FPGM)进行剪枝
和之前看的 [[Network Compression Based on Filter Similarity Pruning for Fast Inference on Edge Devices.pdf | 根据卷积核相似性进行剪枝]] 类似,都是考察卷积核的可替代性,可以用其他的卷积核包含的信息来替代某个卷积核,那么该卷积核即可被删去且对结果影响寥寥。
# distance using numpy function indices = torch.LongTensor(filter_large_index).cuda() weight_vec_after_norm = torch.index_select(weight_vec, 0, indices).cpu().numpy() # for euclidean distance similar_matrix = distance.cdist(weight_vec_after_norm, weight_vec_after_norm, 'euclidean') # for cos similarity # similar_matrix = 1 - distance.cdist(weight_vec_after_norm, weight_vec_after_norm, 'cosine') similar_sum = np.sum(np.abs(similar_matrix), axis=0)
# for distance similar: get the filter index with largest similarity == small distance similar_large_index = similar_sum.argsort()[similar_pruned_num:] similar_small_index = similar_sum.argsort()[: similar_pruned_num] similar_index_for_filter = [filter_large_index[i] for i in similar_small_index]
kernel_length = weight_torch.size()[1] * weight_torch.size()[2] * weight_torch.size()[3] for x inrange(0, len(similar_index_for_filter)): codebook[ similar_index_for_filter[x] * kernel_length: (similar_index_for_filter[x] + 1) * kernel_length] = 0 print("similar index done") else: pass return codebook